Make Your QA Pipelines Talk!

![]()
Question answering works primarily on text, but Haystack provides some features for audio files that contain speech as well.
In this tutorial, we're going to see how to use AnswerToSpeech to convert answers into audio files.
Prepare environment
Colab: Enable the GPU runtime
Make sure you enable the GPU runtime to experience decent speed in this tutorial. Runtime -> Change Runtime type -> Hardware accelerator -> GPU
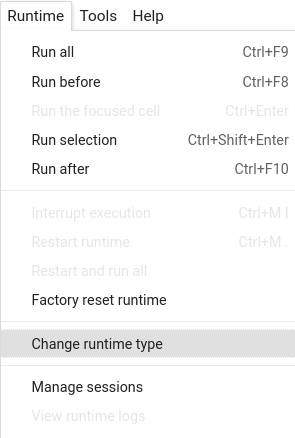
# Make sure you have a GPU running
!nvidia-smi
# Install the latest release of Haystack in your own environment
#! pip install farm-haystack
# Install the latest master of Haystack
!pip install --upgrade pip
!pip install git+https://github.com/deepset-ai/haystack.git#egg=farm-haystack[colab,audio]
Setup Elasticsearch
# Recommended: Start Elasticsearch using Docker via the Haystack utility function
from haystack.utils import launch_es
launch_es()
# In Colab / No Docker environments: Start Elasticsearch from source
! wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.9.2-linux-x86_64.tar.gz -q
! tar -xzf elasticsearch-7.9.2-linux-x86_64.tar.gz
! chown -R daemon:daemon elasticsearch-7.9.2
import os
from subprocess import Popen, PIPE, STDOUT
es_server = Popen(
["elasticsearch-7.9.2/bin/elasticsearch"], stdout=PIPE, stderr=STDOUT, preexec_fn=lambda: os.setuid(1) # as daemon
)
# wait until ES has started
! sleep 30
Populate the document store with SpeechDocuments
First of all, we will populate the document store with a simple indexing pipeline. See Tutorial 1 for more details about these steps.
To the basic version, we can add here a DocumentToSpeech node that also generates an audio file for each of the indexed documents. This will make possible, during querying, to access the audio version of the documents the answers were extracted from without having to generate it on the fly.
Note: this additional step can slow down your indexing quite a lot if you are not running on GPU. Experiment with very small corpora to start.
from haystack.document_stores import ElasticsearchDocumentStore
from haystack.utils import fetch_archive_from_http, launch_es
from pathlib import Path
from haystack import Pipeline
from haystack.nodes import FileTypeClassifier, TextConverter, PreProcessor, DocumentToSpeech
document_store = ElasticsearchDocumentStore(host="localhost", username="", password="", index="document")
# Get the documents
documents_path = "data/tutorial17"
s3_url = "https://s3.eu-central-1.amazonaws.com/deepset.ai-farm-qa/datasets/documents/wiki_gameofthrones_txt17.zip"
fetch_archive_from_http(url=s3_url, output_dir=documents_path)
# List all the paths
file_paths = [p for p in Path(documents_path).glob("**/*")]
# NOTE: In this example we're going to use only one text file from the wiki, as the DocumentToSpeech node is quite slow
# on CPU machines. Comment out this line to use all documents from the dataset if you machine is powerful enough.
file_paths = [p for p in file_paths if "Arya_Stark" in p.name]
# Prepare some basic metadata for the files
files_metadata = [{"name": path.name} for path in file_paths]
# Here we create a basic indexing pipeline
indexing_pipeline = Pipeline()
# - Makes sure the file is a TXT file (FileTypeClassifier node)
classifier = FileTypeClassifier()
indexing_pipeline.add_node(classifier, name="classifier", inputs=["File"])
# - Converts a file into text and performs basic cleaning (TextConverter node)
text_converter = TextConverter(remove_numeric_tables=True)
indexing_pipeline.add_node(text_converter, name="text_converter", inputs=["classifier.output_1"])
# - Pre-processes the text by performing splits and adding metadata to the text (Preprocessor node)
preprocessor = PreProcessor(
clean_whitespace=True,
clean_empty_lines=True,
split_length=100,
split_overlap=50,
split_respect_sentence_boundary=True,
)
indexing_pipeline.add_node(preprocessor, name="preprocessor", inputs=["text_converter"])
#
# DocumentToSpeech
#
# Here is where we convert all documents to be indexed into SpeechDocuments, that will hold not only
# the text content, but also their audio version.
#
# Note that DocumentToSpeech implements a light caching, so if a document's audio have already
# been generated in a previous pass in the same folder, it will reuse the existing file instead
# of generating it again.
doc2speech = DocumentToSpeech(
model_name_or_path="espnet/kan-bayashi_ljspeech_vits", generated_audio_dir=Path("./generated_audio_documents")
)
indexing_pipeline.add_node(doc2speech, name="doc2speech", inputs=["preprocessor"])
# - Writes the resulting documents into the document store (ElasticsearchDocumentStore node from the previous cell)
indexing_pipeline.add_node(document_store, name="document_store", inputs=["doc2speech"])
# Then we run it with the documents and their metadata as input
output = indexing_pipeline.run(file_paths=file_paths, meta=files_metadata)
Querying
Now we will create a pipeline very similar to the basic ExtractiveQAPipeline of Tutorial 1,
with the addition of a node that converts our answers into audio files! Once the answer is retrieved, we can also listen to the audio version of the document where the answer came from.
from pathlib import Path
from haystack import Pipeline
from haystack.nodes import BM25Retriever, FARMReader, AnswerToSpeech
retriever = BM25Retriever(document_store=document_store)
reader = FARMReader(model_name_or_path="deepset/roberta-base-squad2-distilled", use_gpu=True)
answer2speech = AnswerToSpeech(
model_name_or_path="espnet/kan-bayashi_ljspeech_vits", generated_audio_dir=Path("./audio_answers")
)
audio_pipeline = Pipeline()
audio_pipeline.add_node(retriever, name="Retriever", inputs=["Query"])
audio_pipeline.add_node(reader, name="Reader", inputs=["Retriever"])
audio_pipeline.add_node(answer2speech, name="AnswerToSpeech", inputs=["Reader"])
Ask a question!
# You can configure how many candidates the Reader and Retriever shall return
# The higher top_k_retriever, the better (but also the slower) your answers.
prediction = audio_pipeline.run(
query="Who is the father of Arya Stark?", params={"Retriever": {"top_k": 10}, "Reader": {"top_k": 5}}
)
# Now you can either print the object directly...
from pprint import pprint
pprint(prediction)
# Sample output:
# {
# 'answers': [ <SpeechAnswer:
# answer_audio=PosixPath('generated_audio_answers/fc704210136643b833515ba628eb4b2a.wav'),
# answer="Eddard",
# context_audio=PosixPath('generated_audio_answers/8c562ebd7e7f41e1f9208384957df173.wav'),
# context='...'
# type='extractive', score=0.9919578731060028,
# offsets_in_document=[{'start': 608, 'end': 615}], offsets_in_context=[{'start': 72, 'end': 79}],
# document_id='cc75f739897ecbf8c14657b13dda890e', meta={'name': '43_Arya_Stark.txt'}} >,
# <SpeechAnswer:
# answer_audio=PosixPath('generated_audio_answers/07d6265486b22356362387c5a098ba7d.wav'),
# answer="Ned",
# context_audio=PosixPath('generated_audio_answers/3f1ca228d6c4cfb633e55f89e97de7ac.wav'),
# context='...'
# type='extractive', score=0.9767240881919861,
# offsets_in_document=[{'start': 3687, 'end': 3801}], offsets_in_context=[{'start': 18, 'end': 132}],
# document_id='9acf17ec9083c4022f69eb4a37187080', meta={'name': '43_Arya_Stark.txt'}}>,
# ...
# ]
# 'documents': [ <SpeechDocument:
# content_type='text', score=0.8034909798951382, meta={'name': '43_Arya_Stark.txt'}, embedding=None, id=d1f36ec7170e4c46cde65787fe125dfe',
# content_audio=PosixPath('generated_audio_documents/07d6265486b22356362387c5a098ba7d.wav'),
# content='\n===\'\'A Game of Thrones\'\'===\nSansa Stark begins the novel by being betrothed to Crown ...'>,
# <SpeechDocument:
# content_type='text', score=0.8002150354529785, meta={'name': '191_Gendry.txt'}, embedding=None, id='dd4e070a22896afa81748d6510006d2',
# content_audio=PosixPath('generated_audio_documents/07d6265486b22356362387c5a098ba7d.wav'),
# content='\n===Season 2===\nGendry travels North with Yoren and other Night's Watch recruits, including Arya ...'>,
# ...
# ],
# 'no_ans_gap': 11.688868522644043,
# 'node_id': 'Reader',
# 'params': {'Reader': {'top_k': 5}, 'Retriever': {'top_k': 5}},
# 'query': 'Who is the father of Arya Stark?',
# 'root_node': 'Query'
# }
from haystack.utils import print_answers
# ...or use a util to simplify the output
# Change `minimum` to `medium` or `all` to raise the level of detail
print_answers(prediction, details="minimum")
# Sample output:
#
# Query: Who is the father of Arya Stark?
# Answers:
# [ { 'answer_audio': PosixPath('generated_audio_answers/07d6265486b22356362387c5a098ba7d.wav'),
# 'answer': 'Eddard',
# 'context_transcript': PosixPath('generated_audio_answers/3f1ca228d6c4cfb633e55f89e97de7ac.wav'),
# 'context': ' role of Arya Stark in the television series. '
# 'Arya accompanies her father Eddard and her sister '
# 'Sansa to King's Landing. Before their departure, Arya's h'},
# { 'answer_audio': PosixPath('generated_audio_answers/83c3a02141cac4caffe0718cfd6c405c.wav'),
# 'answer': 'Lord Eddard Stark',
# 'context_audio': PosixPath('generated_audio_answers/8c562ebd7e7f41e1f9208384957df173.wav'),
# 'context': 'ark daughters. During the Tourney of the Hand '
# 'to honour her father Lord Eddard Stark, Sansa '
# 'Stark is enchanted by the knights performing in '
# 'the event.'},
# ...
Hear them out!
from IPython.display import display, Audio
import soundfile as sf
# The first answer in isolation
print("Answer: ", prediction["answers"][0].answer)
speech, _ = sf.read(prediction["answers"][0].answer_audio)
display(Audio(speech, rate=24000))
# The context of the first answer
print("Context: ", prediction["answers"][0].context)
speech, _ = sf.read(prediction["answers"][0].context_audio)
display(Audio(speech, rate=24000))
# The document the first answer was extracted from
document = [doc for doc in prediction["documents"] if doc.id == prediction["answers"][0].document_id][0]
print("Document: ", document.content)
speech, _ = sf.read(document.meta["content_audio"])
display(Audio(speech, rate=24000))
About us
This Haystack notebook was made with love by deepset in Berlin, Germany
We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our other work:
Get in touch: Twitter | LinkedIn | Slack | GitHub Discussions | Website
By the way: we're hiring!